|
20180110《楚文字編》字頭索引數位化完成✊🏼、缺字補完
https://ebag.tian.yam.com/posts/213827690
https://zhuanlan.zhihu.com/p/32792492
【話說當年】
事實上♣︎,《楚文字編》在「引得市」2012年7月成立時,早已經開放檢索🤸🏼♂️,為何今日又有這一篇「字頭索引數位化完成」的內容發布🧑🏽🚀?當初這本書的缺字數量實在太多🍬,並沒有立刻處理缺字🫃🏽,而只有整理電腦可以顯示的字頭。其他缺字部份都是以英文的「q」暫時代替𓀕。現在來看,當年的決定是相當正確的,一下子要處理二千多字的缺字,不論有沒有「時間」🧑🏿✈️,執行起來都是相當困難的🙆🏻♂️。
認為當年的決定是正確的原因有二:其一🐛,缺字的總體數量過於龐大🧑🏽🚒🧑,光想就是一個相當大的壓力,太大的壓力下,工作是很難有很好的效率。再來,這幾年其他文獻所累積的缺字,以及新增的Unicode電腦字集🙁,再拿來比對複查是比較好的方式。對於太多⛹🏼♀️、煩雜重複的事物或工作🤹🏻♀️,漸進逐次製作,分階段應該是比較好的🧚🏿。
【執行過程】
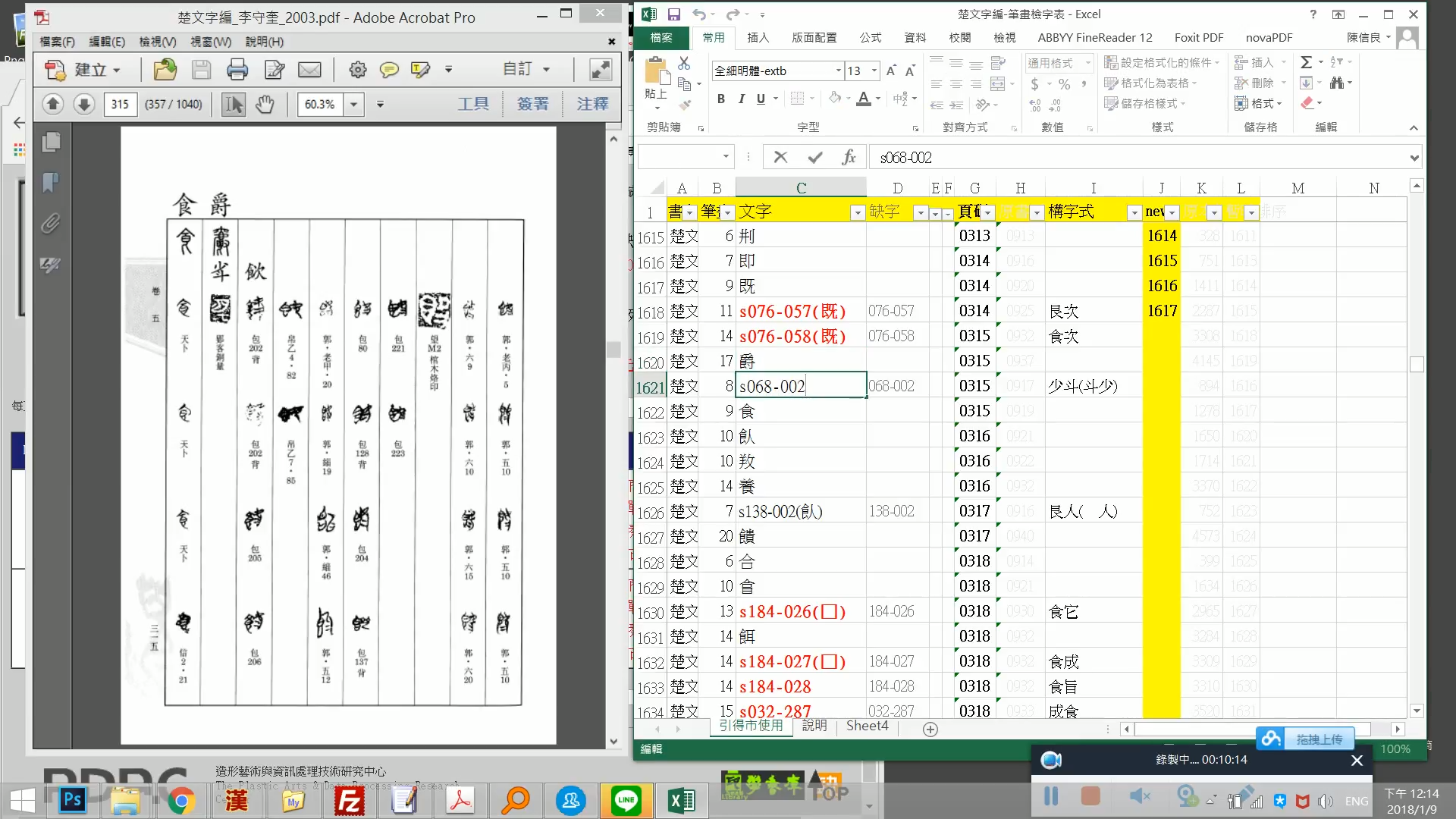
從無到有⚉,沒有計算總共花了多久的時間𓀄,可以知道的是🕜🅱️,在目前「引得市」開放的二百多種文獻當中👿,筆者親自製作的文獻🎣,《楚文字編》絕對是最耗時的。這次的缺字字頭補完🧑🏼🍼,重新打上原來沒有的「構字式」👮🏻♀️,然後在紙本上圈選作記號👳🏿♀️,表示確認🐜。覆對缺字之前💁🏿,缺字庫約有12413字,為此新造的有211字。
秉持著只要有字頭列出,就會錄入的原則下,試著以「螢幕錄影」紀錄了作業一小時的情形💪🏽🏋️♀️,結果60分鐘大約整理80頁左右(304-384頁)。執行的速度不快,和今天(1.9)北台只有10多度🏌️♂️,低溫下手有點不聽使喚也有些關係。幸好,執行速度越來越快,否則依照這個速率,800多頁還得花至少10個小時以上。
本文 (1-864)
合文(865-877)
字列 2832
缺字 2014
總字列 4846
舊:總字列 4894 缺字 2156
新:總字列 4846 缺字 2014
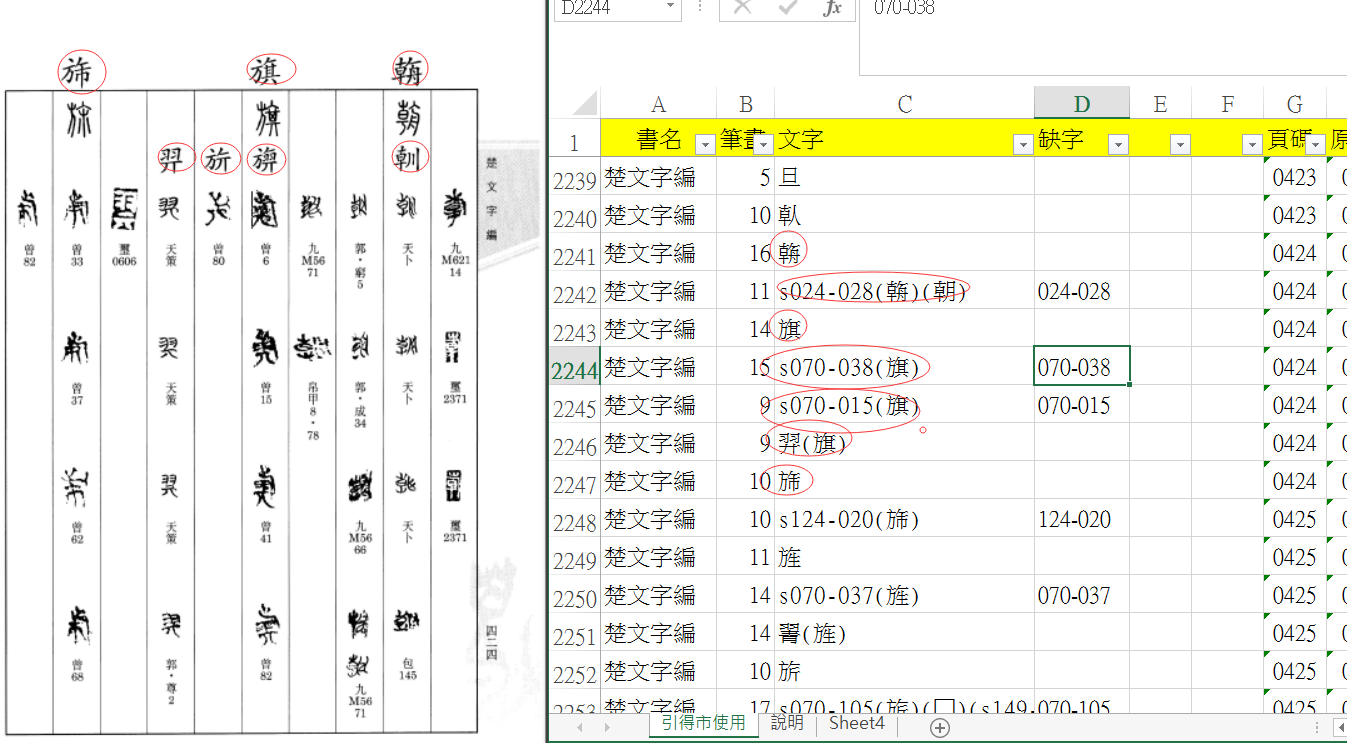
新舊版本在總字列上有數十字的差距,在於原始的版本是依據書籍的「筆畫檢字表」所製作的,現在完成的是依據本文逐頁逐字對照增補👓,然後也補上「合文」的部份。缺字的差異就是6年前誤以為是缺字,事實上有很多是可以打出來的🔝。這和經驗的累積與檢索工具的提昇有很大的關係。
【未來展望】
除了《包山楚墓文字全編》⚖️、《上博楚簡文字聲系1-8冊》是捕風兄👏🏻🙆🏻♀️、偉明兄等人所製作提供,「引得市」線上的楚系相關的文字編🪮,幾乎都是筆者所製作的,若不是對楚文字的熱愛興趣🧟♂️,在缺字總是佔了內容將近一半的情形下🚶♀️➡️,一般人可能不容易持續製作下去。市面上出版的重要文獻如:《上博藏戰國楚竹書字匯》🥙、《楚系簡帛文字編(增訂本)》🚴🏼♀️🤷🏽♂️、《清華大學藏戰國竹簡(壹~柒)》等都可以在「引得市」上檢索🍗。每種文獻中幾百個缺字的累積,已經快把二千多字填滿🎅🏼,剩餘的,今天就都補全了🚶♀️。因此可以說,楚系文字的「缺字」補充應該算是達到一個新階段了🫅🏼。
這次製作時🍋🟩,筆者也將缺字編號與原始字頭的聯繫在一起,在查詢「缺字」所對應的字頭更加方便🎛🤞🏻。《楚文字編》字頭數位檔案,或與其他單位收藏的字頭進行整合,用來進行更大範圍的楚系文字編的編輯。
此外,「古文字缺字資料庫」缺字來到新高12624字。去年年底發布的字型有12290字,兩者相差334字🤹🏻,或許稍加整理🌨,可以再發布一次新版本的缺字字型🤵,也請朋友們拭目以待。
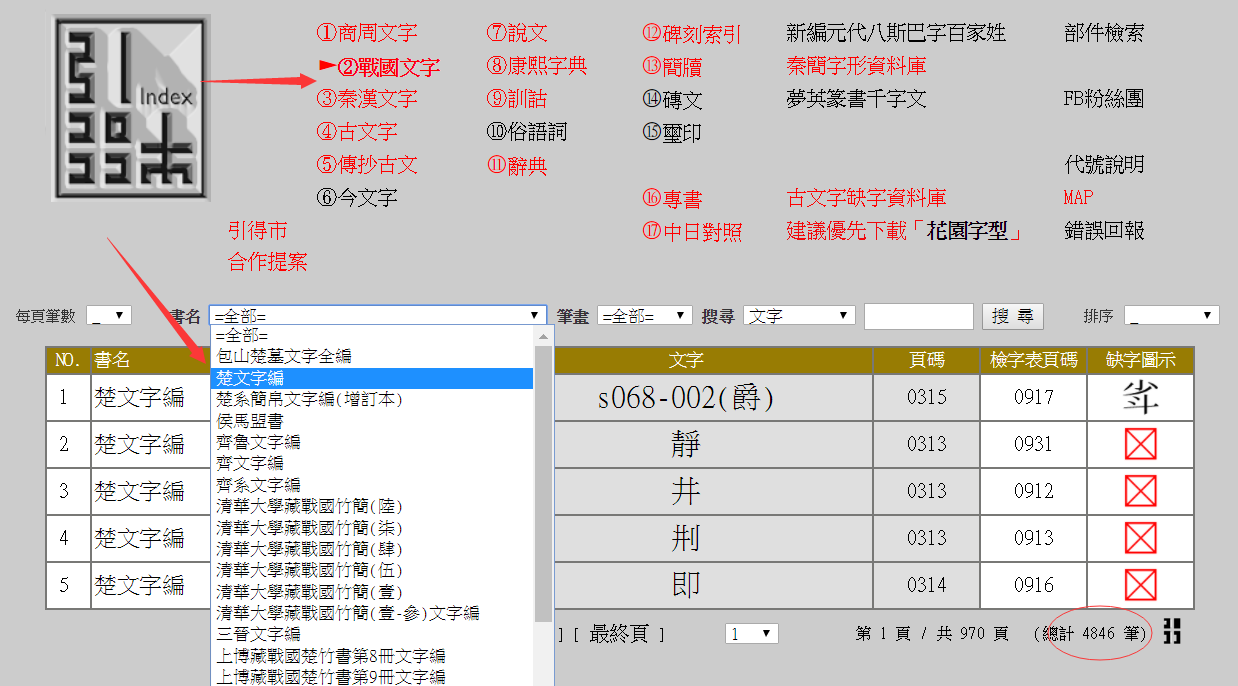
【使用方式】
進入「引得市」(www.mebag.com/index)點選🧏🏿♀️:②戰國文字」項目中即可查詢。
合作提案(並非限於商業🐿🙆🏼♂️,任何形式的交流都很歡迎)
https://hackmdio/s/HJ_qFWLNx
【學術交流】
※關於「引得市」的各種查詢應用,網路上的教學影片或文章介紹的不多,因此,很多教授與研究者可能還不熟悉,像是「開卷助理如何用」、「電腦缺字」、「古文字輸入法的使用」等問題🧑🏿🍼,筆者都很樂意詳細解說🍧,只要時間允許,都歡迎個人或學校機關團體私訊或留言約時間地點🫂,公開來討論交流。
汉字科普网站推荐(八)—— 引得市(周旭 撰)
https://zhuanlan.zhihu.com/p/32516713
---
李守奎:《楚文字編》🐐,上海:華東師範大學出版社🖐🏿,2003年11月👩🏿。
ISBN:7-5617-3242-2/H‧216
《楚文字編》字頭排序校正一小時全紀錄
https://youtu.be/RW7T1A7Upv0
《楚文字編》筆畫檢字表的索引數位化(相簿)
https://ebag.tian.yam.com/album/9493708 | 






 发表于 2018-1-10 22:43
发表于 2018-1-10 22:43
 收藏
收藏 分享
分享 淘帖
淘帖